

728x90
개요
Google Analytics의 데이터를 Big Query를 거쳐 Cloud Storage에 저장하는 방법에 대해 설명합니다.
해당 방법을 사용하기 위해선 GA및 GCP의 요소들이 필요합니다. 다만 크게 요금 부담되지는 않아요. (트래픽이 쩔어주지 않는 다음에야...)
- Google Anlaytics
- GCP Big query
- GCP Function
- GCP Scheduler
- GCP Cloud Storage
스크린샷을 위주로 설명을 진행하겠습니다.
데이터 연동하는 방법
- 선 GA 데이터를 Big Query로 연동합니다. 속성에서 '제품 연결하기 → BigQuery 연결'을 통해 내보내기 설정을 하면 됩니다.

- GCP BigQuery에서 데이터가 들어오는 지 확인합니다. GA 데이터의 경우, 1일 단위로 넘어오는 것과, 스트리밍(실시간)으로 넘어오는 것의 2가지 유형 중 하나를 선택할 수 있는데 analytics 테이블 아래에 1일 단위의 경우 'events_날짜' 이름의 테이블이 하루 단위로 생성되고, 스트리밍 데이터의 경우 'events_intraday_날짜' 이름의 테이블이 1일 단위로 생성됩니다. GCP에서는 에러, 누락 등을 이유로 스트리밍 데이터를 기준으로 쿼리하는 것을 권장하지 않습니다. 그래서 여기서도 그냥 'events_날짜' 테이블을 기준으로 설명을 진행합니다.

- BigQuery에 데이터가 들어오는 것을 확인하면 Cloud Storage로 이동하여 버킷(저장소)를 생성합니다. 메뉴는 좌측 상단의 '메뉴바' 아이콘을 클릭합니다. 여기서는 GCP의 메뉴들을 확인할 수 있습니다. 이 외에도 Cloud Shell 등 Console을 사용하는 방법도 있지만 여기서는 웹에서 설정하는 방법을 기준으로 설명합니다.

- 버킷 이름은 각자 편의대로 생성하면 되고, 데이터 저장 위치 유형은 Region을 선택합니다. 저는 연습용이기 때문에 단일 Region을 선택하였지만 중요 데이터가 있다던가 해서 가용성이 높아야 할 경우 멀티나 듀얼 Region을 선택해도 무관합니다.(물론 비용이 증가합니다.) 그리고 리전 위치는 서울(asia-northeast3)를 선택하였습니다. 이 부분도 각자 상황에 맞춰 선택하면 됩니다. 어쨌든 중요한 것은 별도의 설계가 있는 상황이 아니라면 향후의 Bucket이나 Function이나 동일한 리전에 넣어두는 것이 속 편합니다.

- 데이터는 꾸준히 엑세스할 예정이기 때문에 스토리지 클래스로 Standard를 체크했습니다. 엑세스 제어 방식 역시 여기서는 단일 사용자의 단일 엑세스이기 때문에 '균일한 엑세스 제어'를 선택하였고, 암호화 역시 기본인 'Google 관리 암호화 키'를 선택하였습니다. 다중 사용자가 사용할 경우, 권한로 분리해주고, 암호화 키 또한 상황에 따라 선택할 필요가 있습니다.
- 버킷이 만들어진 것을 확인하면 Cloud Function으로 이동하여 함수를 만들어야 합니다. 여기서는 파이썬3 을 기준으로 설명하겠습니다. 화면에서 '+함수 만들기' 버튼을 클릭합니다.

- 여기서도 기본 설정을 진행합니다. 함수 이름을 사용자가 작성하고 리전은 아까 버킷을 설정할 때와 동일한 리전을 선택합니다. (여기서는 서울 리전) 트리거는 HTTP로 하였는데, 이 경우 함수 실행 트리거 URL이 생성됩니다. 그래서 해당 URL은 외부 노출하게 될 경우 보안상 문제가 발생하니 주의해야 합니다. 그리고 인증은 사용자 별 엑세스를 진행할 경우 '인증필요', URL 만으로 트리거를 실행할 경우 '인증되지 않은 호출 허용'을 선택하게 되는데 여기서는 스케줄러가 자체적으로 실행 가능하게 만들어야 하기 때문에 '인정되지 않은 호출 허용' 을 선택하겠습니다.

- 만일 인증 필요를 체크하였을 경우 Function의 권한에서 권한 → 추가 → 새 구성원 → allUsers를 추가해주면 URL만으로 동작하게 됩니다.

- 설정을 완료하고 다음을 클릭하면 코드 작성으로 넘어가집니다. 저는 여기서 python을 런타임으로 설정하였습니다. 몇가지 주의할 사항이 있는데 GA 데이터의 경우 nested/repeated schema 형태이기 때문에 CSV로 추출할 수 없습니다. CSV로 추출 옵션을 설정할 경우, 그냥 실행되었다고 하는데 아무것도 추출되지 않는 결과가 있을 뿐입니다. 따라서 여기서는 JSON으로 추출하였고, 날짜 별 테이블 정보를 추출하기 위해 Today를 사용하였습니다. 저도 구글링을 통해 아래 코드를 커스텀한 것이고, 여러분들도 코드를 편집하여 사용하면 됩니다. 코드가 배포되면 테스트를 해볼 수 있습니다. 별도의 입력값이 없기 때문에 '작업 → 메뉴바 → 함수 테스트 메뉴'를 통해 그냥 바로 테스트를 진행하면 되고, 로그 역시 확인할 수 있습니다.

# GCP 빅쿼리 라이브러리 가져오기 from datetime import date, timedelta from google.cloud import bigquery # 함수 생성 def export_ga_data(request): project_name = "GA 프로젝트 ID" bucket_name = "저장할 Bucket 이름" dataset_name = "추출할 데이터셋 이름(analytics_****)" # 하루 단위로 추출하기 위한 날짜 설정 yesterday = date.today() - timedelta(days=1) yesterday_str = yesterday.strftime('%Y%m%d') folder_str = yesterday.strftime('%Y_%m') table_name = "events_" + str(yesterday_str) # 목적 URL destination_uri = "gs://{}/{}/{}{}{}".format(bucket_name, folder_str, "ga_export_", yesterday_str, ".json") #Bucket 내부에 folder를 생성하고 그 안에 'ga_export_날짜.json' 형태로 저장 print("URL CHECK : ", destination_uri) # 추출 정보 설정 bq_client = bigquery.Client(project=project_name) dataset = bq_client.dataset(dataset_name, project=project_name) table_to_export = dataset.table(table_name) print("table name Check : ", table_name) # 추출 방식 설정(여기서는 JSON) job_config = bigquery.job.ExtractJobConfig() job_config.destination_format = bigquery.DestinationFormat.NEWLINE_DELIMITED_JSON print("Job Config : ", job_config) # 추출 실행 extract_job = bq_client.extract_table( table_to_export, destination_uri, location="asia-northeast3", job_config=job_config, ) return "Job with ID {} started exporting data from {}.{} to {}".format(extract_job.job_id, dataset_name, table_name, destination_uri)
- 어쨌든 코드가 만들어지면 Scheduler에 해당 코드를 등록해야 합니다. 이제 Cloud Scheduler를 띄운 뒤 '+ 작업만들기' 를 클릭합니다.

- 함수 만들 때와 비슷하게 설정 정보를 입력합니다. 이름과 설명은 사용자 이름대로, 빈도는 Crontab 형식으로 리눅스에서 스케줄러를 사용할 때 쓰는 방식입니다. 자세한 건 아래 REF를 참고하세요. 시간대는 KST(한국표준시)를 선택하였고, 매일 06시에 실행되도록 하기 위해 '00 06 * * *' 과 같이 입력하였습니다. 완료되었으면 계속을 눌러줍니다.

- 계속을 누르면 작업 대상을 지정하는데 여기서 HTTP를 선택할 경우, URL을 입력하게 됩니다. URL은 앞서 Function에서 생성된 트리거 URL로 함수 메뉴의 트리거 에서 확인할 수 있습니다. 현재 URL에 대한 보안이 없기 때문에 외부 노출에 주의해야 합니다. 아무튼 해당 URL을 입력하고, 고급사양은 더 손댈 필요가 없음으로 만들기를 선택합니다.

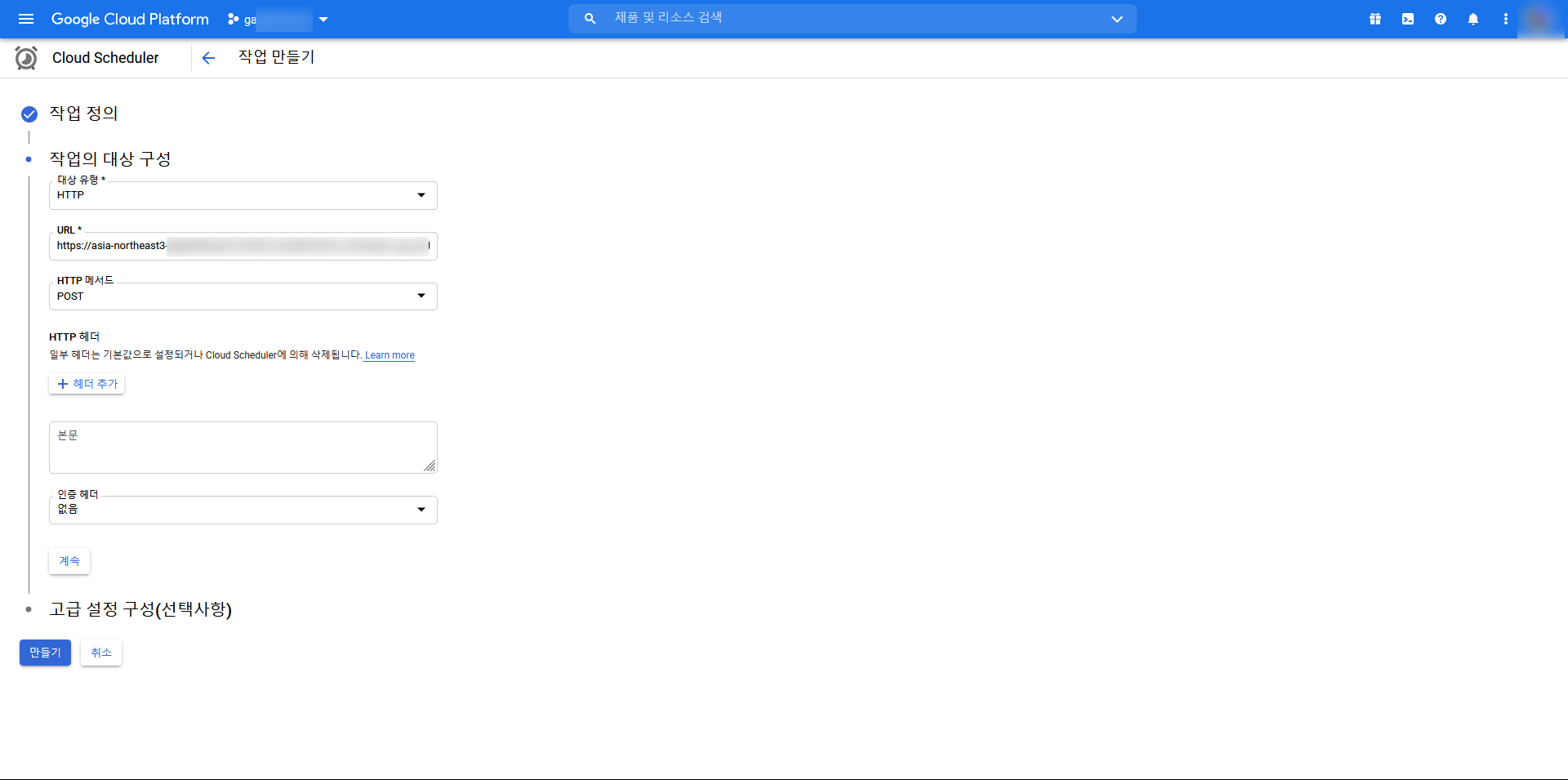
- 그러면 스케줄러가 설정되었습니다. 지금 실행을 클릭하여도 되고, 해당 시간에 실행되는지 직접확인해도 됩니다. 이제 스케줄러가 작동될 경우 아까 설정한 버킷에 Json 데이터가 매일 쌓이는 것을 확인할 수 있습니다!
REF
 https://cloud.google.com/bigquery/docs/exporting-data#python
https://cloud.google.com/bigquery/docs/exporting-data#python https://jdm.kr/blog/2
https://jdm.kr/blog/2
- Function과 Scheduler를 사용한 python 스크립트 실행
Google Cloud Functions과 Cloud Scheduler를 사용해 Python 스크립트 주기적으로 실행하기Google Cloud Functions과 Cloud Scheduler를 사용해 Python 스크립트를 주기적으로 실행하는 방법에 대해 설명한 글입니다 Google Cloud SDK를 설치한 후 아래 글을 읽어주세요
https://zzsza.github.io/gcp/2019/07/07/google-cloud-functions-python/

 https://medium.com/firebase-developers/using-the-unnest-function-in-bigquery-to-analyze-event-parameters-in-analytics-fb828f890b42
https://medium.com/firebase-developers/using-the-unnest-function-in-bigquery-to-analyze-event-parameters-in-analytics-fb828f890b42
- BigQuery 내보내기 관련
BigQuery 스트리밍 내보내기BigQuery 스트리밍 내보내기를 사용하면 BigQuery Export를 통해 몇 분 이내에 당일 데이터를 최신 상태로 만들 수 있습니다. 이 내보내기 옵션을 사용하면 BigQuery에서 사용자 및 속성의 사용자 트래픽에 대해 분석할 수 있는 최신 정보를 확보합니다. 스트리밍 내보내기를 실행하면 각 날짜별로 새로운 테이블 1개와 이 테이블에 해당하는 (BigQuery) 보기 1개가 생성됩니다.
https://support.google.com/analytics/answer/7430726?hl=ko#zippy=%2C%EC%9D%B4-%EB%8F%84%EC%9B%80%EB%A7%90%EC%97%90%EC%84%9C%EB%8A%94-%EB%8B%A4%EC%9D%8C-%EB%82%B4%EC%9A%A9%EC%9D%84-%EB%8B%A4%EB%A3%B9%EB%8B%88%EB%8B%A4
- BigQuery 스트리밍 데이터 관련
Google 애널리틱스 4 속성에 대한 BigQuery ExportBigQuery는 대규모 데이터 세트에 대한 쿼리를 신속하게 처리할 수 있는 클라우드 데이터 웨어하우스입니다. 모든 원시 이벤트를 Google 애널리틱스 4 속성에서 BigQuery로 내보낸 다음 SQL과 유사한 구문을 사용하여 데이터를 쿼리할 수 있습니다. BigQuery에서 데이터를 외부 저장소로 내보내거나 외부 데이터를 가져와서 애널리틱스 데이터와 결합할 수 있습니다.

728x90
'CLOUD' 카테고리의 다른 글
| AWS Athena 쿼리 실행 시 일부 쿼리에서 Limit 무시하는 현상에 대해 (0) | 2022.08.21 |
|---|---|
| AWS lambda에서 계층 추가 시 ‘Layers consume more than the available size of 262144000 bytes’ 오류가 뜰 경우 대처 방안 (0) | 2022.08.19 |
| AI-900 자격증 시험 후기 (2) | 2021.07.04 |
| [AZ-900] 시험 후기 및 공부 방법 (4) | 2021.05.16 |
| [AZ-900] 가격과 지원(500) (0) | 2021.05.07 |
| [AZ-900] 보안, 규정준수, 개인정보보호, 신뢰(400) (0) | 2021.05.05 |